:: Artículo de Pilar Bustos para DivulgaUNED (http://www.divulgauned.es). Publicado bajo Licencia Creative Commons BY 3.0 Unported ::
En un mundo donde la ciencia avanza a un ritmo inalcanzable, cada día se tienen más conocimientos sobre la diversidad de las especies, las enfermedades o la mejora de cultivos agrícolas. En este sentido, hoy en día, todo parece pasar por la genética. Por ejemplo, el gen Prdm9 parece ser el responsable de la aparición del perro a partir del lobo; el gen ApoE4 parece estar asociado con un mayor riesgo de padecer alzhéimer; la obtención de cultivos transgénicos precisa de modificaciones de los genes de las especies vegetales cultivadas, y un largo etcétera. Pero, ¿qué es la genética?, ¿qué son los genes?, y, ¿por qué son tan importantes?
Hay que empezar este pequeño paseo definiendo qué es un gen. La RAE (Real Academia Española de la Lengua) define gen como la “secuencia de ácido desoxirribonucleico (ADN) que constituye la unidad funcional para la transmisión de los caracteres hereditarios”. En verdad, esta definición, no dista mucho de las definiciones más sencillas que podemos encontrar en los libros de biología: un gen es una serie de nucleótidos que contiene la información necesaria para sintetizar una proteína. Los genes contienen la información genética y son responsables de la transmisión de los caracteres hereditarios a la descendencia.
Cuando se habla de caracteres hereditarios, se hace referencia a los rasgos (morfológicos, anatómicos, fisiológicos, conductuales, bioquímicos, citológicos, moleculares…) transmitidos por los genes. O, de una forma más simple, estos caracteres hereditarios son esos rasgos por los que popularmente se dice eso de “te pareces a…”, “eres igual a… cuando tenía tu edad”, “tienes los mismos… (ojos, gestos) que…”. Pero, como la propia definición indica, no solo son rasgos visibles o de comportamiento, sino que, también se refieren a aspectos como la salud, como es el caso de enfermedades hereditarias, es decir patologías de los padres o abuelos que también padecen los hijos.
De los guisantes a la doble hélice
En este punto se hace necesario hablar de Gregor Johann Mendel (1822-1884). El científico fue un monje y naturalista austriaco. Conocido por llevar a cabo experimentos con guisantes que le permitieron formular las tres conocidas “Leyes de Mendel” (postuladas en el año 1865), fueron estas leyes las que asentaron la base de la herencia genética. Sin duda, Mendel es recordado por muchos puesto que, en España, sus leyes son objeto de estudio en la asignatura de Biología en la Educación Secundaria Obligatoria (E.S.O.). Aunque es un aspecto importante recordar el trabajo de Mendel, no vamos a profundizar, el menos en este artículo, sobre sus leyes.
 Aunque el naturalista estableció cómo se transmitían los caracteres de los padres a los hijos en el año 1865, previamente a ligar la transmisión de estos caracteres hereditarios con los genes, diversos estudios independientes tuvieron que salir a la luz para llegar a comprobar esa asociación. Entre 1868 y 1869, Friedrich Miescher aisló por primera vez ADN, al que inicialmente se le denominó nucleina, hasta que fue definido por Richard Altmann como ácido nucleico en el año 1889, procedente de muestras de pus.
Aunque el naturalista estableció cómo se transmitían los caracteres de los padres a los hijos en el año 1865, previamente a ligar la transmisión de estos caracteres hereditarios con los genes, diversos estudios independientes tuvieron que salir a la luz para llegar a comprobar esa asociación. Entre 1868 y 1869, Friedrich Miescher aisló por primera vez ADN, al que inicialmente se le denominó nucleina, hasta que fue definido por Richard Altmann como ácido nucleico en el año 1889, procedente de muestras de pus.
Además, de forma previa al descubrimiento del ADN y, al establecimiento de las Leyes de Mendel (1865), dos científicos, Karl Wilhelm von Nägeli y Edouard Van Beneden, consiguieron de forma independiente observar, en el año 1842, los cromosomas dentro de las células.
Años después del descubrimiento de la “nucleina” y de la existencia de los cromosomas, en 1881, Edward Zacharias demuestra experimentalmente que los cromosomas están formados por nucleina.
Los experimentos llevados a cabo por Walter Sutton y Theodor Boveri permitieron establecer en 1902 que la clave de la transmisión de los caracteres hereditarios se localiza en los cromosomas. No obstante, este hecho no fue reconocido por el total de la comunidad científica hasta que Thomas Hunt Morgan (Premio Nobel de Fisiología y Medicina en 1933) publicó, en 1910, sus experimentos sobre los caracteres hereditarios ligados al sexo.
El establecimiento total de que los genes, responsables de la transmisión de los caracteres hereditarios, están formando los cromosomas tuvo lugar en 1912, gracias a las demostraciones realizadas por Calvin Bridges y Nettie Stevens. Asentándose las bases de la herencia genética en 1915 tras la publicación del libro “El mecanismo de la herencia mendeliana” escrito por Thomas H. Morgan, Alfred Strurtevant, Hermann Müller y Calvin Bridges.
Volviendo a esa sustancia aislada, a partir de muestras de pus por Friedrich Miescher, el ADN, su composición química fue identificada en el año 1919 por Phoebus Levene. Según este investigador, el ADN está formado por unidades más pequeñas, llamadas nucleótidos que, químicamente consisten en un azúcar (glucosa), un grupo fosfato y una base nitrogenada. Aunque, no fue hasta el año 1943, gracias al trabajo realizado por Oswald Avery, C McLeod y M McCarty, que se determinó que los genes, localizados en los cromosomas y, responsables de la herencia de los caracteres, estaban formados por ácidos nucleicos. Diez años más tarde, en 1953, James Watson y Francis Crick publicarían la estructura tridimensional del ADN, la conocida doble hélice de DNA, que les haría ganar el Premio Nobel de Fisiología y Medicina en el año 1962.
Un alfabeto distinto
Cuando se habla de genes, es muy habitual referirse a codificar. Los genes codifican proteínas. Y, esto, ¿qué significa? Las proteínas se definen como una cadena de aminoácidos. Pero podemos ir aún más lejos y es que, si los genes son los encargados de transmitir los caracteres de padres a hijos, las proteínas son las responsables de la manifestación de esos caracteres.
Las proteínas pueden tener funciones estructurales, es decir formar parte de cada una de las células que constituyen nuestro cuerpo (la melanina que da color a la piel, la keratina que forma parte de las uñas, la miosina de los músculos); o pueden tener función enzimática, en este caso, la proteína es responsable de todas y cada una de las reacciones que tienen lugar en nuestro cuerpo (por ejemplo, la insulina que transporta la glucosa desde la sangre a los tejidos es una proteína).
Pero, ¿cómo un gen se transforma en proteína? En realidad, el material genético (ADN) y las proteínas están escritos en idiomas distintos. Así, el ADN es una secuencia de nucleótidos y las proteínas de aminoácidos. De modo que, las células tienen mecanismos para equiparar ambos “lenguajes”.
En el caso del ADN, las bases nitrogenadas que lo forman pueden ser de cuatro tipos: adenina (A), timina (T), citosina (C) y guanina (G). Es por ello que, el ADN y, en consecuencia un gen, estará constituido por una secuencia de estas cuatro letras (ATCG) que se dispondrán de una forma concreta según cada gen. En este sentido, la secuencia de un gen determinado tiene una combinación específica de estas cuatro bases. Así, cuando hablamos de especies distintas, por ejemplo, el hombre y el cerdo, el hecho de que el 90% del genoma sea idéntico en ambas especies, indica que el 90% del ADN tiene una secuencia similar.
Pero, nuestras células no conocen este lenguaje del ADN. Imaginemos la situación que se nos presentaría si de repente nos encontramos frente a una puerta cerrada un letrero que dice “добрыйвечер”. ¿Qué haríamos con esta información? Inicialmente nada porque, salvo que conozcamos el idioma ruso, no seremos capaces de interpretar este texto en este contexto. Lo mismo le ocurre a una célula cuando se encuentra con la secuencia de nucleótidos de un gen (por ejemplo, gen de la hemoglobina 2 de la planta Arabidopsis thaliana, “AA TAT TCG TGT TTT TTT CAA ACT GTG AGA GAA AAA GAA AGA GAG AAA GAG ATG GGA GAG ATT GGG TTT ACA GAG AAG CAA GAA GCT TTG GTG AAG GAA TCG TGG GAG ATA CTG AAA CAA GAC ATC CCC AAA TAC AGC CTT CAC TTC TTC TCA CAG TAA CCA TAT ATA CTT AGT TAT ATA TAA GCT CTT TAC ATG TTG TTT ATA TAT GCG AGC TAA TGA ACA ATA TAA TTG TGA TAG GAT ACT GGA GAT AGC ACC AGC AGC AAA AGG CTT GTT CTC TTT CCT AAG AGA CTC AGA TGA AGT CCC TCA CAA CAA TCC TAA ACT CAA AGC TCA TGC TGT TAA AGT CTT CAA GAT GGT AAT TAC TTA CTT TCC GAT TTT CCA CAT CTA CAT ATA TGT GAA TCA CTT GCA TAT ACT GTA TCA TTA TCT TAC CAT TCC TTA AAA TTG AAA GTA GAA TGT TTC ATT ATT TAC AGC TAA GAA TCT TTA TTT ACT CAT TAT ATA CCA TTT ATA TAT AAT AGA AAA TAG TAG TCT GAA TTA ACT TTT CTT GTC ATT TAT TGA CGC AGC CAT GTG CAC ACA AGT TGC GAT TTT GTT TGA ACT TGG CTA GTT GGC TTT GTC TTC TTC TTT GAG AAT AAA AAT CTC ATA CTA GTA AAG AAT ACT CTG TGA TAT TTT ATT TTT AAG AAC AAA CAT AGA TTT CTC TGT CAA TAA AGA ATT GTT ACT GAA GAA TCC AAG TGG TTC GGG TCG CTT TAT GGA TTT TTA CTT TTT TGC TAA TCT TAT TAT AAT AGA ACC ATA TAA ACC AAA TTC CGT TTA CTT TTT AAA TTT GGG TTT ATG ACT TGG TTT GGT TCA ACT CAC TTT TGG CTT CTA AGA CTT TGC ATA ACA TGT TTT AGA CAG ACA AAA AAG AAA AAG ACTT GCA TAA CAT GTA TGA ATT TTT ATT TTA TTT TGT TTG TGT GTA GAC ATG TGA AAC AGC TAT ACA GCT GAG GGA GGA AGG AAA GGT GGT AGT GGC TGA CAC AAC CCT CCA ATA TTT AGG CTC AAT TCA TCT CAA AAG CGG CGT TAT TGA CCC TCA CTT CGA GGT CTG TTA TGT TAA AAA AAA ATA TAT ATA CAC ATT AAT TTT GGC TGA TTT TGA TTT TCG ATT TGA ACG CAT TTT AAT AAG GTG TGA ATG TGA AAG CAG GTG GTG AAA GAA GCT TTG CTA AGG ACA TTG AAA GAG GGG TTG GGG GAG AAA TAC AAT GAA GAA GTG GAA GGT GCT TGG TCT CAA GCT TAT GAT CAC TTG GCT TTA GCC ATC AAG ACC GAG ATG AAA CAA GAA GAG TCA TAA AAC CCT ATT GAT CAT TGG GTA TCG CAT ACA TGA ATC TAT TCC ACA T”).
Ahora bien, si no conocemos el ruso y, ni siquiera somos capaces de descifrar el cirílico pero, tuviésemos a nuestra disposición los medios necesarios para traducir el mensaje de “добрыйвечер”, ¿qué es lo primero que haríamos? Probablemente, buscar un mecanismo para identificar las letras cirílicas. De esta forma, lograríamos saber que en realidad en el letrero el mensaje es “добрый вечер” (está formado por dos palabras y no por una sola), una vez conocido esto, haríamos una identificación de las letras para realizar una transcripción fonética (es decir, buscar el equivalente de los sonidos de las letras cirílicas en letras latinas): “dobri becher”.
Algo parecido le pasa a las células con los genes. Los genes están formados por regiones llamadas intrones y exones que no son más que, secuencias codificantes (es decir, contienen un mensaje) y secuencias no codificantes separando las anteriores. Para eliminar estas regiones no codificantes, el ADN sufre un proceso llamado transcripción, por el cual, el ADN pasa a ácido ribonucleico (ARN), el ARN mensajero está formado también por una combinación de cuatro bases nitrogenadas (A, C, G y Uracilo-U, que sustituye a la T del ADN) y tan sólo contiene la secuencia codificante del gen.

Si consideramos nuevamente el gen de la hemoglobina 2 de la planta Arabidopsis thaliana, la secuencia de su RNA mensajero sería: “ATG GGA GAG ATT GGG TTT ACA GAG AAG CAA GAA GCT TTG GTG AAG GAA TCG TGG GAG ATA CTG AAA CAA GAC ATC CCC AAA TAC AGC CTT CAC TTC TTC TCA CAG ATA CTG GAG ATA GCA CCA GCA GCA AAA GGC TTG TTC TCT TTC CTA AGA GAC TCA GAT GAA GTC CCT CAC AAC AAT CCT AAA CTC AAA GCT CAT GCT GTT AAA GTC TTC AAG ATG ACA TGT GAA ACA GCT ATA CAG CTG AGG GAG GAA GGA AAG GTG GTA GTG GCT GAC ACA ACC CTC CAA TAT TTA GGC TCA ATT CAT CTC AAA AGC GGC GTT ATT GAC CCT CAC TTC GAG GTG GTG AAA GAA GCT TTG CTA AGG ACA TTG AAA GAG GGG TTG GGG GAG AAA TAC AAT GAA GAA GTG GAA GGT GCT TGG TCT CAA GCT TAT GAT CAC TTG GCT TTA GCC ATC AAG ACCG AGA TGA AAC AAG AAG AGT CAT AA”.
Una vez que, tenemos nuestro mensaje más “claro”, el siguiente paso sería recurrir a alguien con el que podamos contactar y le podamos preguntar el significado de “dobri becher” o emplear el ordenador para conseguir un traductor digital (el cual no lo hubiésemos podido usar sin el paso intermedio al no conocer la posición de las letras cirílicas en un teclado). Es decir, necesitaríamos realizar una traducción para lograr saber que en el letrero dice “buenas tardes”. En el caso de las células, también existe este proceso (igualmente llamado traducción). La información transcrita en el ARN mensajero se traduce a proteínas en unas estructuras celulares llamadas ribosomas.
El degenerado código genético
Ahora bien, ¿qué problema tuvieron que afrontar los científicos que comenzaron a estudiar este código? La información genética viene dada por la combinación de cuatro nucleótidos, mientras que las proteínas pueden estar formadas por la combinación aminoácidos, existiendo 20 aminoácidos distintos. De modo que, el nuevo reto para los científicos de la época fue conocer la equivalencia entre los nucleótidos y los aminoácidos.
Si había una relación 1:1 (1 nucleótido-1 aminoácido), entonces, no podría haber más de cuatro aminoácidos. En el caso de que existiese una equivalencia 1:2, tan sólo podrían existir 16 aminoácidos. Este problema fue resuelto por George Gamow en 1954. Según Gamow, el código genético se basaba en un código de codones en el que la combinación de tres nucleótidos determinaría un aminoácido. Esta sería la combinación mínima de nucleótidos necesaria para la existencia de al menos 20 aminoácidos.
Estas predicciones teóricas llevadas a cabo por Gamow fueron verificadas por Francis Crick que demostró experimentalmente que los codones constan de tres nucleótidos, en el año 1958; y, tres años más tarde, por los estudios llevados a cabo por Francis Crick, Sydney Brenner, Marshall Nirenberg y Heinrich Matthaei que, descubrieron la primera correspondencia codón-aminoácido. Posteriormente, el establecimiento del código genético (que determina las correspondencias de los codones, formados por tripletes de nucleótidos, con los aminoácidos) se debió al trabajo de tres grupos principalmente: el grupo de Marshall Warren Nirenberg, el grupo de Har Gobind Khorana y, el grupo del español Severo Ochoa.
De esta forma, siguiendo con el ejemplo de la hemoglobina 2 de la planta Arabidopsis thaliana, la secuencia de aminoácidos para esta proteína sería: “M G E I G F T E K Q E A L V K E S W E I L K Q D I P K Y S L H F F S Q I L E I A P A A K G L F S F L R D S D E V P H N N P K L K A H A V K V F K M T C E T A I Q L R E E G K V V V A D T T L Q Y L G S I H L K S G V I D P H F E V V K E A L L R T L K E G L G E K Y N E E V E G A W S Q A Y D H L A L A I K T E M K Q E E S”. Siendo los aminoácidos: valina (Val, V), leucina (Leu, L), treonina (Thr, T), lisina (Lys, K), triptófano (Trp, W), histidina (His, H), fenilalanina (Phe, F), isoleucina (Ile, I), arginina (Arg, R), metionina (Met, M), alanina (Ala, A), prolina (Pro, P), glicina (Gly, G), serina (Ser, S), cisteína (Cys, C), asparagina (Ans, N), glutamina (Gln, Q), tirosina (Tyr, Y), ácido aspártico (Asp, D) y, ácido glutámico (Glu, E).
Sin embargo, algo no parece encajar con el código genético. Teniendo en cuenta que los codones están formados por la combinación de tres nucleótidos, el número total de codones posibles es de 64. Pero, tan sólo existen 20 aminoácidos, de modo que, ¿qué ocurre con los 44 codones restantes? La clave para responder a esta pregunta está en la degeneración del código genético.
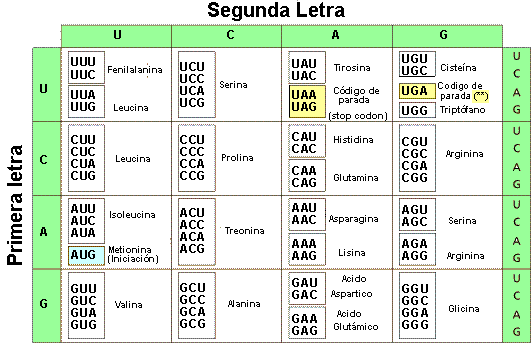
Que el código genético está degenerado quiere decir que distintos codones pueden codificar, es decir, corresponderse, para un mismo aminoácido. Si bien, esto podría parecer ilógico ya que, siguiendo con el símil de los idiomas, para nosotros no es lo mismo una vaca que una baca, ni ahí y hay u, ojear y hojear. Pero como se suele decir, la naturaleza es sabia. Si bien, lo mismo que ocurre con los traductores digitales, los mecanismos de traducción de la célula también pueden cometer errores y, provocar un cambio de nucleótido en la secuencia del RNA mensajero (fenómeno conocido como mutación) que puede dar lugar o no, gracias a esta degeneración del código genético, a cambios en la correspondencia del codón con los aminoácidos. Estos cambios de nucleótidos, si producen un cambio del aminoácido correspondiente, puede traer consecuencias negativas ya que, pueden afectar a la proteína, alterando su función. De hecho, siguiendo con la lingüística, el mensaje que se transmite cuando decimos “tengo una vaca” o “tengo una baca” no es para nada el mismo.
Para ver la relevancia de los cambios de nucleótidos sobre la secuencia de la proteína, podemos hacer referencia a las numerosas enfermedades producidas por una mutación, como por ejemplo: la celiaquía, que se debe a una mutación en el gen HLA (Human Leukocyte Antigen); la hemofilia, por la mutación del gen G2021A que codifica la proteína Protrombina; o, la displasia de cadera, producida por una mutación del gen que codifica la Fibrilina 2 (gen FBN2).
En definitiva, que el código genético esté degenerado, es un mecanismo más de defensa contra mutaciones que pueden afectar a la proteína y comprometer la supervivencia del individuo. Si reflexionamos sobre ello, esta degeneración permite al mecanismo de traducción de la célula interpretar el mensaje aunque haya errores. Así, si nosotros leemos una nota escrita por una persona no hispanoparlante en la que se señale: “he visto una baca pastando en el prado”, todos sabemos que, en realidad lo que ha visto es una vaca.
Pilar Bustos, estudiante del máster de Periodismo Científico de UNED. Artículo publicado en divulgaUNED. Reproducido en Bionaturex bajo Licencia Creative Commons Reconocimiento 3.0 Unported. Si va a reproducirlo, cite al autor: divulgaUNED.
